FEATURED
FEATUREDApplication Development & Modernization
Uplift enterprise IT with cloud-native modernization services that transform critical applications and empower peak performance.
Simplify the AI conversation. Build, scale, and optimize the way your business does AI.
Cut through the complexity of cloud technology and unlock its full potential with multi and hybrid cloud solutions and services.
Unlock collaboration that uplifts your organizations with cloud-based tools from Microsoft and Cisco to bring teams together.
Conquer security compliance complexities with targeted advising and assessment tailored to your company’s unique circumstances.
Consolidate your data management with an actionable plan for your business data.
Leverage DevOps and cloud-native principles to achieve business goals, enhance software delivery, and future-proof infrastructure.
Tailored solutions in Digital Commerce, Digital Marketing and overall Digital Strategy, unlocking your organization’s true potential.
Empowering better business starts with a better, modern data center.
Design a reliable networking solution around the requirements of your organization.
Transition from manual processes to streamlined, automated workflows for managing modern networks
Implement secure, scalable, and repeatable security measures shaped to serve your specific business needs.
Stay ahead of network needs and the competition with tailored optical transport and network infrastructure solutions.
 FEATURED
FEATURED FEATURED
FEATURED FEATURED
FEATURED FEATURED
FEATURED FEATURED
FEATURED FEATURED
FEATURED
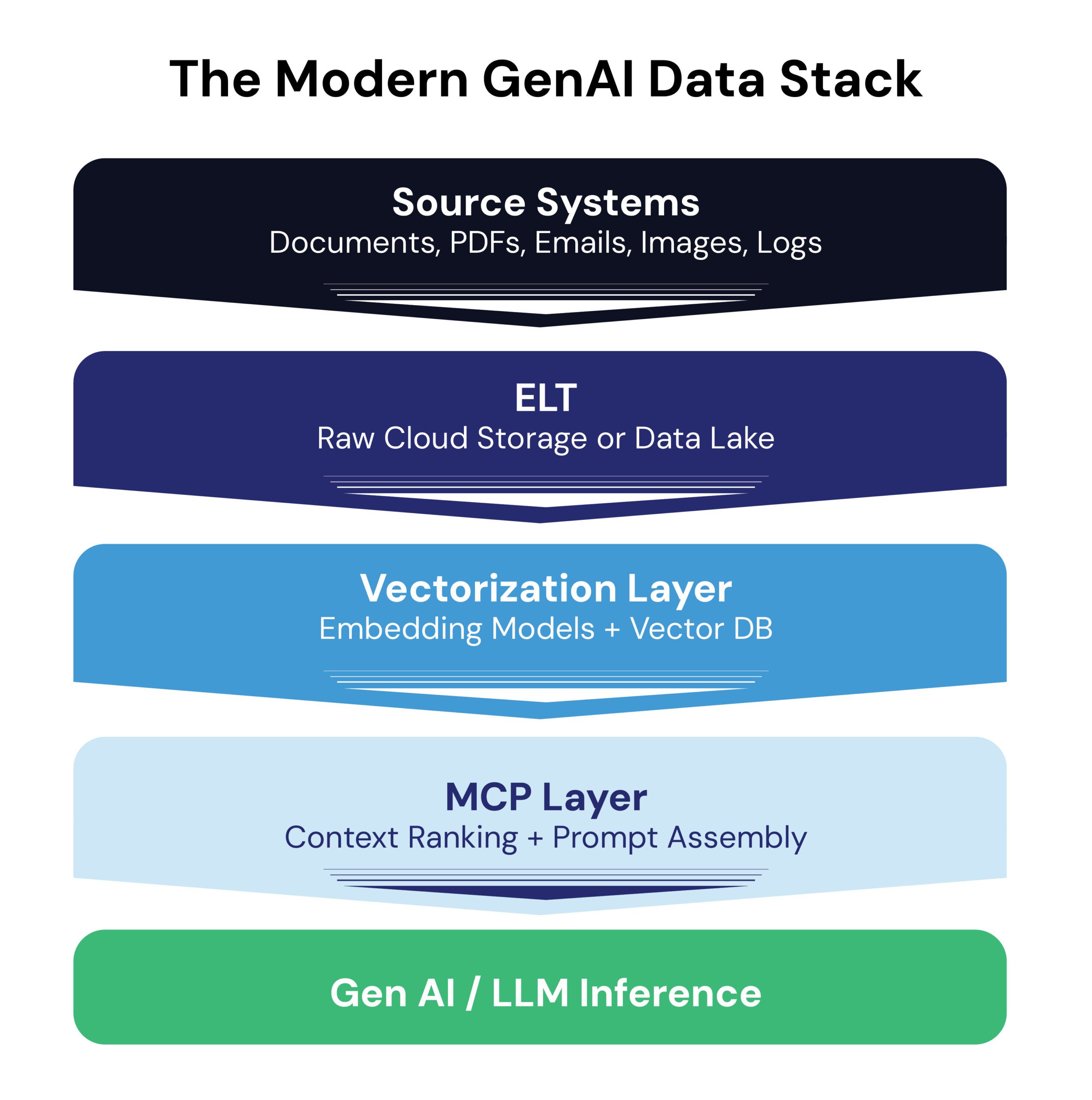
Generative AI has fundamentally changed how enterprises architect data pipelines. In our previous post, we explored how ELT (Extract, Load, Transform) still plays a foundational role, helping teams ingest and store full-fidelity data. However, in the AI era, simply having access to raw information is no longer sufficient.
Modern large language models (LLMs) and multi-modal systems require structured, semantically rich context to reason effectively. That’s why AI-native stacks now extend beyond ELT to include two essential layers: vectorization and Model Context Packaging (MCP).
This blog explores how each layer contributes to building intelligent, adaptive systems:
ELT – Ingest and preserve raw, unstructured data at scale
Vectorization – Convert that data into semantic, retrievable embeddings
MCP – Package context dynamically to optimize model understanding
ELT remains the fastest and most scalable method for centralizing enterprise data. It extracts information from multiple systems and loads it into data lakes or cloud warehouses, preserving original formats for downstream use.
For GenAI use cases, ELT enables:
Speed of ingestion – Consolidate disparate data sources quickly
Flexibility – Retain raw formats like PDFs, logs, or SQL for future reuse
However, ELT alone doesn’t make data AI-ready. LLMs cannot reason over gigabytes of unstructured content without additional layers that surface semantic meaning. ELT is where pipelines begin—but it’s not where intelligence starts.
Once raw data is centralized, the next step is making it searchable by meaning—not just keywords. That’s the role of vectorization.
Vectorization transforms unstructured and multi-modal data (documents, images, logs, videos, etc.) into embeddings: high-dimensional vectors that capture conceptual relationships. This enables semantic retrieval, allowing systems to return results based on intent.
For example, semantic search can differentiate between “Apple the company” and “apple the fruit” based on context.
Chunking – Divide large documents or files into smaller, retrievable units
Tokenization & Embedding – Use models such as Cohere, OpenAI, or SigLIP to generate vector representations
Metadata Tagging – Include dimensions like document type, timestamp, and permissions
Storage & Search – Store vectors in databases optimized for Approximate Nearest Neighbor (ANN) search (e.g., Pinecone, Weaviate, FAISS)
Dynamic Reranking – Apply models like ColBERT or LLM rerankers to prioritize relevant chunks
Vectorization is the cornerstone of Retrieval-Augmented Generation (RAG), enabling search experiences that are contextual, responsive, and intelligent.
A global law firm vectorizes its massive contract archive, breaking it into clauses, tagging them with legal metadata, and storing embeddings in a vector database. Legal teams can then retrieve clauses in real time using GenAI or semantic search—accelerating research and reducing manual review.
Beyond improving search, vectorization enables truly context-aware GenAI interaction. But one more layer is needed to make that context usable by an LLM.
Even with embeddings, raw retrieval isn’t enough. LLMs need curated context to perform reliably. Model Context Packaging (MCP) is the process of bundling:
Relevant data chunks (retrieved via vector search)
Metadata and relationships (to preserve meaning)
Instructions or prompts (tailored to the use case)
MCP ensures that models receive the right information at the right time. It powers more effective RAG pipelines and agent-based workflows.
A retail chatbot combines ERP inventory data with product manuals and policy PDFs using MCP. When a client asks about a product, the system compiles the most relevant details—stock levels, specifications, warranty language—and delivers a context-rich prompt to the LLM. The result is a fast, accurate, and personalized response—without human intervention.
Ultra-long context windows (up to 1 million tokens) in models like GPT-4.1 and Claude 3.5
Adaptive retrieval – Dynamically fetch context only when needed, optimizing costs
Ephemeral memory – Enable agents to temporarily store and update knowledge in real time
In short, MCP bridges the gap between retrieved data and actionable AI outputs.
As AI adoption accelerates, three major trends are reshaping how pipelines are designed:
Agentic AI Systems – Pipelines are no longer passive; they’re powering agents that reason, plan, and act autonomously.
Context Explosion – Longer context windows allow LLMs to work with more nuanced data without extensive summarization.
Self-Optimizing Pipelines – Adaptive systems now refine their own retrieval, embeddings, and context strategies based on usage and performance.
Enterprises that invest in ELT, vectorization, and MCP today are well-positioned to support next-generation capabilities tomorrow.
Whether you’re building your first AI application or scaling a GenAI platform across departments, BlueAlly helps you move beyond traditional pipelines to develop AI-ready architectures that understand, retrieve, and act on the data that matters most.
Through strategic partnerships with Legion, Kamiwaza, and other ecosystem players, we integrate vectorization and MCP capabilities into your existing architecture—minimizing disruption and maximizing AI impact.
At BlueAlly, we reveal the simplicity inside complexity by making technology more accessible, more certain, and more impactful.